RISPONDIAMO A QUALCHE TUA CURIOSITA’
Dettagli infrastrutturali
AIDeskPro +Massima segregazione del dato
AIDeskPro + risiede su Google Cloud, all’interno dell’Organizzazione di Open Gate o del Cliente.
Ad esso è dedicato un Progetto ad hoc, all’interno del quale gira un’istanza dedicata di AIDeskPro, con il suo database dedicato.

Sicurezza dei dati
Criptazione at-restMassima sicurezza del dato
AIDeskPro risiede su Google Cloud. I dati, documenti… che vengono caricati in AIDeskPro sono criptati.
I dati all’interno dell’infrastruttura GCP sono soggetti ad una Crittografia at-rest predefinita, attuata come default da Google.
Tutti i dati vengono criptati utilizzando l’algoritmo AES (Advanced Encryption Standard), AES-256.

Sicurezza dei dati
Criptazione in transitoMassima sicurezza del dato
Il dato è criptato anche quando esce dall’infrastruttura Google Cloud che ospita AIDeskPro.
L’encryption in transito avviene via HTTPS.
Tutte le infrastrutture progettate per AIDeskPro, in tutte le versioni, prevedono un Classic Application Load Balancer, dotato di protocollo HTTPS.

Motori Gen AI
Google e OpenAII motori utilizzabili
AIDeskPro consente di utilizzare una pluralità di servizi di generative AI offerti da Google e OpenAI.
Questi motori sono selezionabili da parte dell’utente e sono: Chat GPT 4, Gemini Pro, GPT 4 Turbo 128k, Chat Bison, Code Chat Bison… e altre loro varianti.
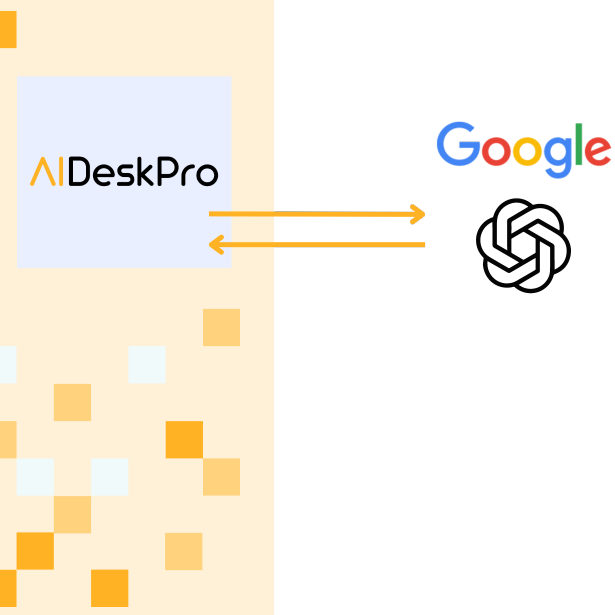
Cosa viene passato
Utilizzo dei motori GenAIMassima privacy sul dato
Un utente di AIDeskPro carica uno o più documenti, creando un Indice e, successivamente, crea un Chat per interrogare questo Indice.
AIDeskPro passa, al servizio di genAI prescelto dall’utente, il Prompt ovvero il testo della domanda e parti pertinenti dell‘indice e ciò avviene in modalità criptata (HTTPS).
Il servizio di terze parti analizza quanto ricevuto, formula una risposta che invia di ritorno ad AIDeskPro, Nulla è conservato dal servizio di Gen AI delle informazioni preliminarmente fornite o della risposta data.
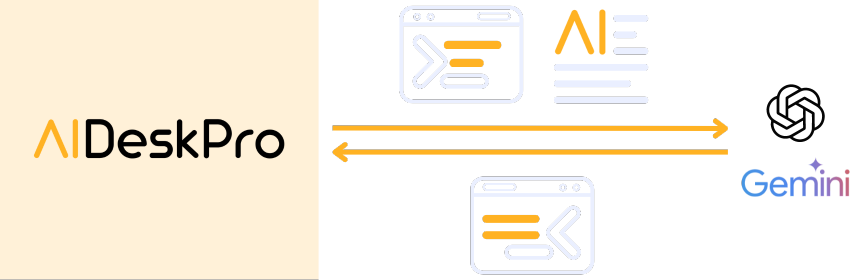
Domande successive
Utilizzo dei motori GenAIMassima privacy sul dato
L’utente creatore della Chat, fatta la prima domanda riferita ad un Indice, può decidere di porre anche ulteriori successive domande, sempre nella medesima chat.
Come può il motore di gen AI prescelto, rispondere, tenendo conto di quanto già detto in precedenza, se tutte le informazioni non vengono conservate?
Si occupa AIDeskPro di risolvere il problema: ad ogni successiva richiesta nell’ambito di una stessa chat, il sistema passa al motore di Gen AI l’ultima domanda fatta, tutte le domande e risposte fatte in precedenza nella chat e parte dei documenti.

Risposte diverse
Randomicità della rispostaLa Temperatura
Ponendo più volte ad AIDeskPro la stessa domanda, lui risponderà sempre in modo diverso (non nel contenuto, salvo lievi differenze, ma nella forma): perché ciò accade?
I modelli di generative AI sono dotati di una parametro definibile Temperatura, che determina la randomicità della risposta, il grado di fantasia che è loro concesso applicare…
Per Gemini tale parametro può variare da 0 a 1 (a valori più alti corrisponde maggiore randomicità), per Open AI tale parametro può variare da 0 a 2 (anche in questo caso, a valori più alti corrisponde maggiore randomicità).
Le impostazioni default dei modelli, usate anche da AIDeskPro, sono, ad oggi, 0.9 per Gemini e 1 per Open AI.
Attinenza delle risposte
Gestita dall'UtenteI Prompt Custom
Un utente crea un Indice e pone delle domande: per poter formulare le risposte, i motori di generative AI attingeranno alle informazioni contenute nei documenti forniti ed anche a conoscenze di carattere generale (documentazione pubblica su qualsiasi argomento, che i fornitori dei servizi di gen AI danno in pasto ai motori stessi).
Se l’utente di AIDeskPro ha necessità di ricevere risposte solo ed esclusivamente attingendo alle informazioni dell’Indice, è possibile forzare il tool a farlo utilizzando il Prompt custom associato all’Indice da interrogare.
L’utente potrà fornire, all’interno del Prompt, le regole di utilizzo dell’Indice, forzando il Tool ad usare solo le informazioni contenute nei documenti forniti.
Token e Contesto
Cosa sono?Token e Contesto
Un Token in termini di elaborazione del linguaggio naturale, è il più piccolo pezzo di dati utilizzato come elemento informativo. Un token equivale a circa quattro caratteri ovvero 100 token corrispondono a circa 60-80 parole. Quando si fornisce la dimensione della finestra di Contesto di un LLM, ci si riferisce al numero massimo di token che il modello è in grado di considerare come input durante la generazione di risposte.
AIDeskPro mette a tua disposizione anche modelli da ben 128.000 token!
Vuoi altre informazioni?
Puoi trovare ulteriori dettagli tecnici all’interno dei documenti ufficiali dedicati alla Privacy ed al Data Processing Addendum.
In particolare, in coda al DPA, troverai due allegati:
- Prodotti e Servizi di terze Parti, che descrive nel dettaglio i servizi utilizzati e gli accordi stipulati con le Società proprietarie di questi servizi
- Misure tecniche ed organizzative per garantire la sicurezza dei dati, che descrive le procedure applicate in tema di sicurezza del dato
Il DPA è a disposizione della tua azienda e, in caso di acquisto di AIDeskPro, potrai richiedere la tua copia sottoscritta tra le parti.
